My Covariance Matrix
is Better Than
Your Shit-Tier LLM
are gonna have notes.
that's fine.
A few years ago I went to the most technical ML talk at BSW.
The speaker asked who in the room was technical.
about 20% of the hands went up.
For a research town like Boulder, that's a fucking bad sign.
I'm not an ML researcher. I run a couple of rooms.
- Boulder New Tech (took it over a year ago, it's been around 17)
- Builders' Room at BSW (3 years and counting)
- Threshold Labs (geometric stuff in neural nets)
- Have lived here ~12 years and watched some things
This talk is the one I've been punting on for three years. It's the one I want to give.
When did we all forget that the most powerful tools we have are the ones we learned in high school?
For a lot of real problems, simple math beats your LLM.
- Cheaper
- Faster
- Inspectable
- Updates in real time when new data shows up
- Doesn't need a vendor
This is not "LLMs are bad." LLMs do things a covariance matrix can't. But we've been so dazzled we stopped asking whether the problem has structure we could exploit directly.
Even Karpathy thinks LLMs are too damn big.
Recent work: microgpt (4,192 params) and nanochat (a working ChatGPT clone for under $100).
"LLM size competition is intensifying, backwards. Models are big because we're asking them to memorize the internet, not because reasoning needs that scale."
Translation: most problems don't need that much model. They need the right structure.
Here's the thing nobody tells you. These techniques are all the same family.
Every one of them is asking a slightly different question about the same matrix. Once you see the family, the buzzwords stop being scary. They become moves you make depending on the question you have.
// none of this is new. most of it predates the iPhone.
What do we actually want to know?
Each one wins when you ask a specific question.
Covariance / co-occurrence
K-Means
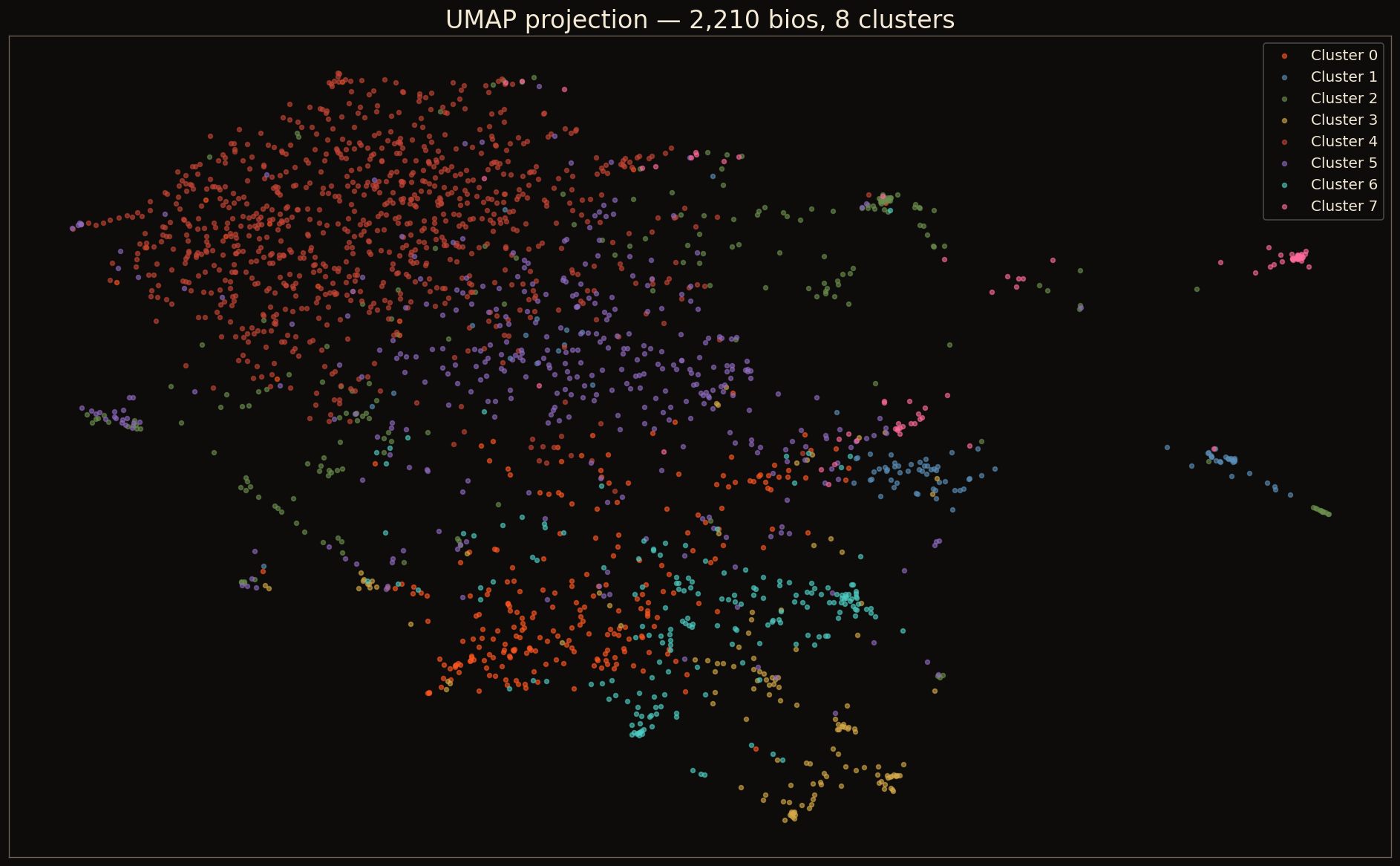
UMAP
Maximal Marginal Relevance
Isolation Forest
Large Language Model
You don't pick one. You stack them.
The LLM does one sentence of work. The math does everything else.
Classify a community by skills and interests.
Input: bios from a real, regional tech community you probably care about.
Goal: figure out what people do, what they're into, and who clusters with whom.
// no API key. no GPU. no vendor.
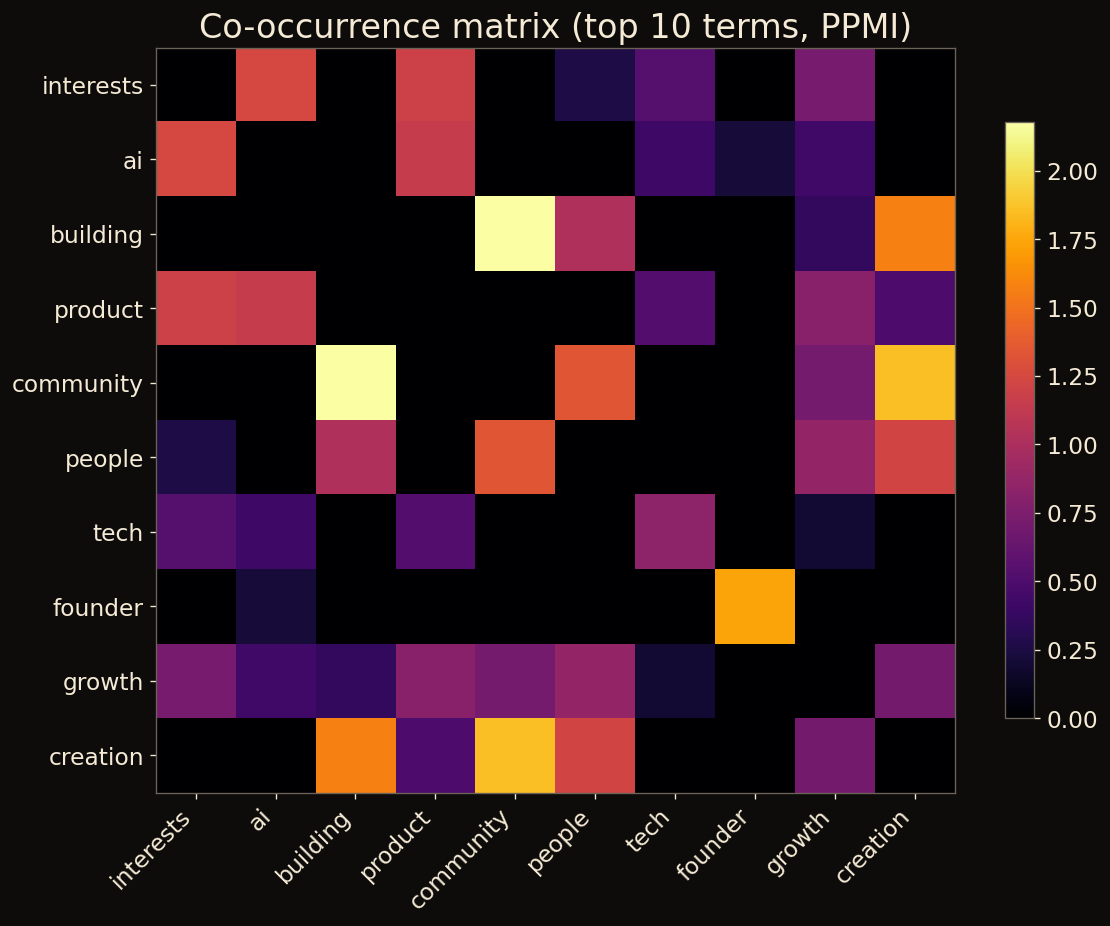
Someone in the audience submits a bio. The matrix updates. Live.
No retraining. No fine-tuning run. No "please wait while we redeploy."
You can watch the geometry of the room change as new data arrives.
An LLM classification is frozen at training time. It doesn't know about the person who registered yesterday. The matrix does. By design.
Now I add the rest of the family. Same data. Five questions.
- K-means on the matrix → personas emerge from the data. No taxonomy needed up front.
- UMAP on the matrix → 2D map of the room you can look at. Show clusters as points.
- Isolation Forest → interdisciplinary outliers. The people who don't fit any cluster cleanly are usually the most interesting in the room.
- MMR on the matrix → "give me 5 people relevant to AI but diverse from each other" — useful for panel curation.
All of this on a laptop. None of it called an LLM.

So how do you actually vibe code with this in mind?
The default failure mode of vibe coding is the LLM wrapper.
You ask a coding agent to solve a problem. It reaches for the most legible solution: call an LLM. Wrap a function around it. Return JSON. Ship.
It works. It demos great. And then:
- You can't update without re-prompting
- You can't see why it made a decision
- It costs money every time it runs
- It hallucinates and you don't notice for weeks
- The shape of your data doesn't matter to the code
You've outsourced not just the computation but the understanding of your problem to a vendor. You can't reason about your own product anymore.
The fix isn't to stop using assistants. It's to stay in the math seat.
Coding assistants are extraordinary at typing. They are mediocre at deciding what should be typed. That's your job.
If you walk in with the geometry of your problem clear in your head, the assistant becomes a power tool. If you walk in with vibes, it becomes a slot machine.
How to keep the math front and center.
Same task. Two prompts. Watch what changes.
Prompt B doesn't need an LLM at runtime. It needed one in your head.
While we're here. Let's look at the technical/non-technical split in our own data.
self-described technical, by their own words, in their own bios.
I'm not editorializing. I'm showing you what the matrix found.
// the unsupervised approach didn't pre-decide what "technical" means.
// the clusters emerged from the language people used about themselves.
Where to go from here.
The starter kit
To go deeper
If you liked covariance
Right tool. Right problem. Know what your tool is doing.
Boulder has the ingredients. The researchers. The builders. The weirdos.
The point of this talk wasn't to dunk on LLMs. It was to make a room where the PhD from CU and the non-technical founder can both feel like the conversation is worth their time.
You don't need to be an expert to ask better questions. You just need to remember the math you already know and use it to connect with the people who know more.
— ryan / threshold labs / boulder new tech
Find me. Build something.


